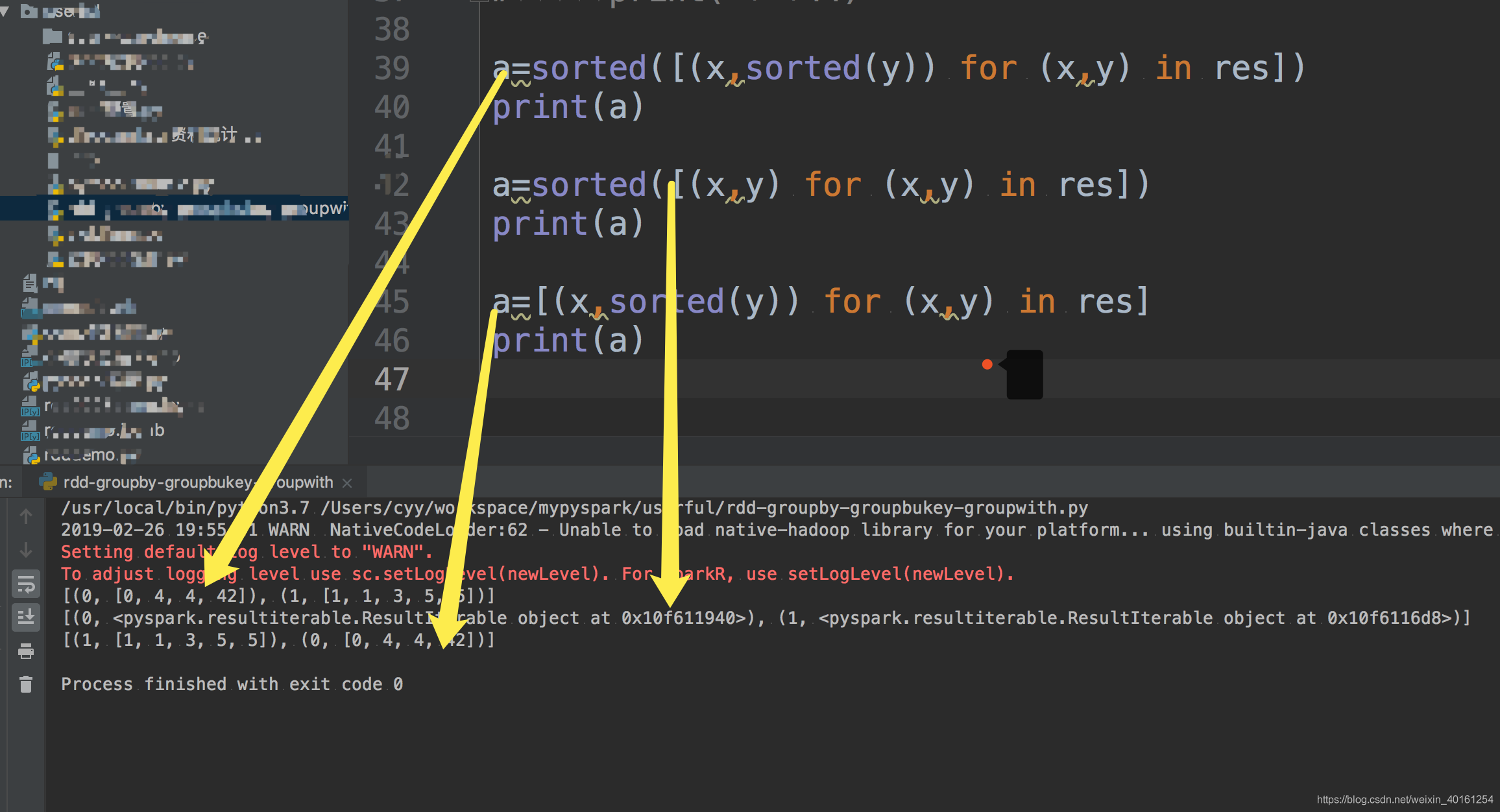
Partition By Key Pyspark. the repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Columnorname) → dataframe [source] ¶. When you call repartition(), spark shuffles the data across the network to. the repartition() function in pyspark is used to increase or decrease the number of partitions in a dataframe. Ultimately want to use is this. Ideally into a python list. to match partition keys, we just need to change the last line to add a partitionby function:. what's the simplest/fastest way to get the partition keys? at the moment in pyspark (my spark version is 2.3.3) , we cannot specify partition function in repartition function. pyspark partitionby() is a function of pyspark.sql.dataframewriter class which is used to partition the large dataset (dataframe) into smaller files based on one or multiple columns while writing to disk, let’s see how to use this with python examples. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. pyspark partition is a way to split a large dataset into smaller datasets based on one or more partition keys.
from blog.csdn.net
Columnorname) → dataframe [source] ¶. what's the simplest/fastest way to get the partition keys? the repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Ultimately want to use is this. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. at the moment in pyspark (my spark version is 2.3.3) , we cannot specify partition function in repartition function. the repartition() function in pyspark is used to increase or decrease the number of partitions in a dataframe. Ideally into a python list. When you call repartition(), spark shuffles the data across the network to. to match partition keys, we just need to change the last line to add a partitionby function:.
Partition By Key Pyspark to match partition keys, we just need to change the last line to add a partitionby function:. pyspark partition is a way to split a large dataset into smaller datasets based on one or more partition keys. pyspark partitionby() is a function of pyspark.sql.dataframewriter class which is used to partition the large dataset (dataframe) into smaller files based on one or multiple columns while writing to disk, let’s see how to use this with python examples. Columnorname) → dataframe [source] ¶. the repartition() function in pyspark is used to increase or decrease the number of partitions in a dataframe. When you call repartition(), spark shuffles the data across the network to. what's the simplest/fastest way to get the partition keys? Ideally into a python list. to match partition keys, we just need to change the last line to add a partitionby function:. This operation triggers a full shuffle of the data, which involves moving data across the cluster, potentially resulting in a costly operation. at the moment in pyspark (my spark version is 2.3.3) , we cannot specify partition function in repartition function. the repartition() method in pyspark rdd redistributes data across partitions, increasing or decreasing the number of partitions as specified. Ultimately want to use is this.